


ABSTRACT
Concerning the Amyotrophic Lateral Sclerosis (ALS) and other diseases related to the Locked-in Syndrome (LiS), the communication ability of the patients is compromised, harming their lives. Quality of life is the main contributing factor for rising life expectancy, and rehabilitation activities along with technological tools play an essential role in this process. As a component of an alternative communication system, which is currently in development, this work presents a Computer Vision (CV) and Machine Learning (ML) approach for the blink detection task while allowing the eye blink as a communication signal. The system was tested using the public dataset Closed Eyes In The Wild (CeW) and provides promising results.
Paulo Augusto de Medeiros1,2– paulo.augusto@lais.huol.ufrn.br
Ricardo Alexsandro de Medeiros Valentim2 – ricardo.valentim@lais.huol.ufrn.br
Gabriel Vinicius Sousa da Silva – gabriel.vinicius@lais.huol.ufrn.br
Daniele Montenegro da Silva Barros2 – daniele.barros@lais.huol.ufrn.br
Hertz Wilton de Castro Lins2– hertz.lins@lais.huol.ufrn.br
Felipe Ricardo dos Santos Fernandes2– felipe.ricardo@lais.huol.ufrn.br
Danilo Alves Pinto Nagem2– danilo.nagem@lais.huol.ufrn.br
- Presenter: Computer Science undergraduate student at UFRN. Currently researching Deep Learning approaches on Natural Language Processing and Computer Vision tasks. Also interested in studying Algorithms and Data Structures.
- Laboratory of Technological Innovation in Health (LAIS), UFRN, Natal, Brazil
Computer Vision and AI applied to blink detection for communication interface for ALS patients
- INTRODUCTION
ALS is a neurodegenerative disease that affects in a progressive and irreversible manner both inferior and superior motor neurons and, after a certain stage, compromises communication and movement abilities of the patient. Both computer vision and machine learning fields, concerning LiS related diseases, have allowed the development of technological tools with significant contributions, including alternative communication systems. These systems improve the patient’s quality of life and may contribute to increasing life expectancy[1].
There are several approaches for interacting with an alternative communication system: electroencephalogram (EEG), electromyography (EMG) and electrooculogram (EOG) devices and also infrared cameras (IR). However, these are complex approaches for domestic usage and/or require expensive and specialized hardware. The work presented by Krolak and Strumiłło [2] provides and validates an approach using standard webcams (without IR) while employing the eye-blink as the communication signal. However, the challenge of developing a real-time communication system remains open with regard to their process. Thus, this work aims to build a low latency and low error rate deep learning model for eye-state classification and blink detection using only the webcam for data acquisition. Voluntary blinks are the chosen communication signal for the system. Since involuntary blinks are associated with short blinks, voluntary blinks are considered to be long.
- MATERIALS AND METHODS
The proposed approach to the blink detection problem firstly solves the eye-classification task on each frame of the captured webcam images and then analyzes these outputs as a binary sequence. Segments of consecutive positives outputs are, thus, a blink. The overall architecture of the system is defined upon five different steps (see Figure 1): (i) frame capture, (ii) face detection, (iii) regions-of-interest (ROI) segmentation, (iv) eye-state classification and, finally, (v) blink detection. These steps will be detailed below.
The first step deals with the capture of the frame, followed by face detection. In order to accomplish the latter, a Single Shot MultiBox Detector (SSD) is employed. This model is an extension of Convolutional Neural Networks (CNNs). CNNs are well-known image encoders. Firstly presented at [3], this architecture works by progressively shrinking the input image into smaller (with lower width and height) representations, until a one-dimensional representation is achieved. The shrinking process is due to the application of convolutional filters which weights are learned during the training phase of the model. The SSD architecture utilizes these intermediate representations for the object detection task, evaluating bounding boxes at each cell of these representations. Bounding boxes with high scores can then be considered relevant detections.

The ROI segmentation step is supported by two preliminary substeps: facial landmarks extraction and face alignment. Facial landmarks are key points of a given face. A set of five facial landmarks is used. Once the landmarks are extracted, the Umeyama [4] algorithm is used for face alignment. The ROI for each eye are then extracted from the aligned face.
A CNN is used at the classification step. The aforementioned image encoder capacity of CNNs can be easily combined with a classification network and thus provide a simple image classifier. For this work, a neural network is used for classifying the computed encoding into either closed or open eye; thus, a binary classifier. The architecture of the combined models is depicted in Figure 1. Since the system is expected to work within low latency, a simple, yet efficient, architecture was chosen. Each frame will then be attributed to a binary value: 1 in case of a closed eye and 0 otherwise.
The last step is the blink segmentation step. In this step, consecutive positive (1) values will be segmented as a blink. However, not all blinks shall be considered. Since the aim of this work is to use voluntary blinks as a communication signal, only long blinks, as stated in Section 1, will be extracted as signals. Thus, only sequences longer than an established threshold will be considered. This value indicates the minimum length of a blink in order to consider it long.
- EXPERIMENTS AND RESULTS
Since the main contribution of the presented work is the proposed CNN preceded by the ROI extraction step, two experiments were conducted in order to evaluate its effectiveness. The experiments were executed on a Intel® Core™ i5-7200U CPU @ 2.50GHz × 4, with 8Gb RAM, using Ubuntu 20.04.1 LTS as Operating System.
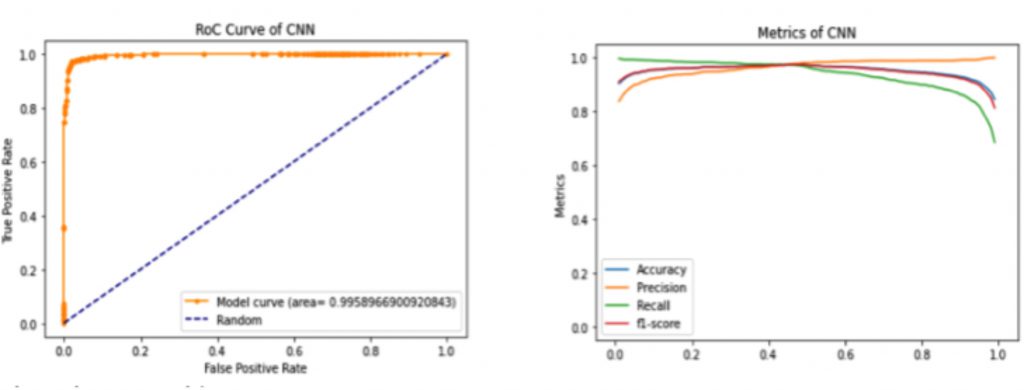
The first experiment consists of evaluating accuracy, precision, recall, F1-score and Area Under Curve (AUC) on the Cew dataset [5]. The CeW dataset was built specially for the eye-state classification task, concerning the unconstrained real-world scenario, which presents challenging characteristics such as different angles, lightning conditions, blurring and occlusion. This dataset consists of 1192 open-eyed images and 1231 closed-eyed images.
The second experiment consists of evaluating the average running time and standard deviation of the whole system and its steps. The system was tested during 30 seconds and the running times of each station were computed. This test will be executed 30 times in order to achieve statistical significance.
The Pytorchframework was used to build and to train the convolutional architecture.
The OpenCV and Dlib libraries were used for image manipulation and landmarks extraction, respectively. The Umeyama algorithms implementation was extracted from the scikitlibrary. Also, the face detection model was the UltraLight[6].
The results of the first experiment are depicted in Figure 2. The model achieved 0.996 on the AUC score and 0.97 on both accuracy and f1-score. Compared to other works, [5] achieved 0.9694 and [7], 0.98. Therefore, the proposed model presents promising and comparable results. It is thus expected that such results reflect positively when extended to a binary sequence, providing great efficiency to the model.
| Station | Average Running Time (ms) | Standard Deviation (ms) |
| Frame Capture | ~4 | < 1 |
| Face Detection | ~21 | < 1 |
| ROI segmentation | ~4 | < 1 |
| Eye-state Classification | ~5 | < 1 |
| Blink Detection | < 1 | < 1 |
| Whole system | ~35 | ~2 |
Table 1 – Computed average running times and standard deviations for each step and for the whole system.
The results of the second experiment are described in Table 1. Overall, low latency and low standard deviation can be observed for all steps, and therefore, for the whole system. The Eye-state Classification step represents the proposed CNN, and its low latency confirms the simplicity of the architecture. Furthermore, the low latency combined with the low standard deviation of the whole system indicates its real time capacity, i.e. ability of working over 25 frames per second.
- CONCLUSION FUTURE WORK
This work proposed a real time communication system using the eye-blink as a communication signal. The sophisticated architectures employed in this system assure quality to the system. The experiments show the low-latency and low-error specs of the system, indicating application capacity at the proposed constraints.
As future work, extensions of the presented system will be investigated as well as their evaluation on videos, instead of only image datasets. Furthermore, the construction of a dataset regarding the specific application constraints will be attempted.
REFERENCES
[1] J. P. Rosa Silva et al., “Quality of life and functional independence in amyotrophic lateral sclerosis: A systematic review,” Neuroscience & Biobehavioral Reviews, vol. 111, pp. 1 – 11, 2020.
[2] A. Królak and P. Strumiłło, “Eye-blink detection system for human–computer interaction,” Universal Access in the Information Society, vol. 11, no. 4, pp. 409–419, Nov 2012. [Online].
[3] Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE 86 (1998) 2278–2324.
[4] S. Umeyama, Least-squares estimation of transformation parameters between two point patterns, IEEE Trans. Pattern Anal. Mach. Intell. 13 (1991) 376–380.
[5] F. Song, X. Tan, X. Liu, S. Chen, Eyes closeness detection from still images with multi-scale histograms of principal oriented gradients, Pattern Recognition 47 (2014) 2825–7582838. doi: https://doi.org/10.1016/j.patcog.2014.76003.024.
[6] Linzaer, Ultra-lightweight face detection model, 2020. URL: https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB.
[7] Y. Li, M. Chang, S. Lyu, In ictu oculi: Exposing ai created fake videos by detecting eye blinking, in: 2018 IEEE International Workshop on Information Forensics and Security (WIFS), 2018, pp. 1–7.
Biography
Paulo Augusto de Lima Medeiros, currently Computer Science undergraduate student at UFRN, paulo.augusto@lais.huol.ufrn.br
Presently researching Machine Learning approaches on Natural Language Processing and Computer Vision tasks. Also interested in studying Algorithms and Data Structures focusing mainly on ICPC competitions such as Maratona de Programação and Machine Learning algorithms.
Paulo Augusto de Medeiros1,2– paulo.augusto@lais.huol.ufrn.br
Ricardo Alexsandro de Medeiros Valentim2 – ricardo.valentim@lais.huol.ufrn.br
Gabriel Vinicius Sousa da Silva – gabriel.vinicius@lais.huol.ufrn.br
Daniele Montenegro da Silva Barros2 – daniele.barros@lais.huol.ufrn.br
Hertz Wilton de Castro Lins2– hertz.lins@lais.huol.ufrn.br
Felipe Ricardo dos Santos Fernandes2– felipe.ricardo@lais.huol.ufrn.br
Danilo Alves Pinto Nagem2– danilo.nagem@lais.huol.ufrn.br
- Presenter: Computer Science undergraduate student at UFRN. Currently researching Deep Learning approaches on Natural Language Processing and Computer Vision tasks. Also interested in studying Algorithms and Data Structures.
- Laboratory of Technological Innovation in Health (LAIS), UFRN, Natal, Brazil





{kind=link}