

ABSTRACT
Oggigiorno l’introduzione dell’Intelligenza Artificiale nei processi industriali è diventato un aspetto strategico nelle industrie manifatturiere. Una delle applicazioni più diffuse è quella di sistemi software di supporto alla gestione di problemi di qualità. I metodi di diagnosi tradizionali si basano su modelli probabilistici, che effettuano inferenze su una base di conoscenza precostruita.
Il sistema proposto in questo paper è stato realizzato nel 2018 presso un plant produttivo di elettrodomestici da cucina. Il modello utilizzato è una rete bayesiana che effettua inferenze su una base di conoscenza costruita con l’esperto del processo.
I risultati ottenuti, dopo aver messo in funzione il sistema, confermano la validità dell’approccio utilizzato: dopo due anni di lavoro, il sistema raggiunge quasi il 95% di diagnosi corrette “al primo colpo”.
Alla luce dei risultati ottenuti e considerando i dati raccolti nei due anni di lavoro, abbiamo progettato l’evoluzione del sistema presentato. Avendo a disposizione un consistente volume di dati, che sono stati raccolti in questi due anni, costruiremo la base di conoscenza con un approccio di tipo deep learning. Si tratta di un modello a rete neurale che presenta più strati nel layer hidden.
Il modello di rete scelto appartiene alla classe delle recurrent neural network, volendo rappresentare un comportamento dinamico dal punto di vista temporale.
Nicola BERGANTINO (n.bergantino@mynext.it), Gianluca CAPUZZI (g.capuzzi@mynext.it), Domenico CARBONE (d.carbone@mynext.it)
Paper
L’intelligenza Artificiale in fabbrica: sistema di supporto alle decisioni per problemi di qualità
Introduzione
L’evoluzione dell’Intelligenza Artificiale ha portato alla sua applicazione in nuovi ambiti. Nei processi industriali, oggigiorno, l’introduzione di questa disciplina è diventata un aspetto strategico che porta un elevato valore aggiunto, soprattutto nelle industrie manifatturiere. Una delle applicazioni più diffuse è quella di sistemi software di supporto alla gestione di problemi di qualità [1]. In queste applicazioni, i metodi di diagnosi tradizionali si basano su modelli probabilistici, che effettuano inferenze su una base di conoscenza precostruita.
Questo paper propone un sistema realizzato nel 2018 presso un plant produttivo di elettrodomestici da cucina [2]. Il modello utilizzato è una rete bayesiana dinamica che effettua inferenze su una base di conoscenza che viene costruita con l’esperto del processo. Il sistema, dopo aver effettuato la diagnosi, chiede un feedback all’operatore e successivamente propone un piano di azioni per la risoluzione del problema. La scelta del piano da proporre si basa sulla teoria dell’utilità: il sistema sceglie il piano che massimizza l’utilità attesa. Dopo aver eseguito il piano di azioni, l’operatore restituisce un feedback al sistema, il quale aggiorna il rating di quel piano, in relazione al problema di qualità diagnosticato. Questa tecnica si basa sull’apprendimento per rinforzo con un modello costruito ad hoc per l’assegnazione della “ricompensa”.
I risultati ottenuti confermano la validità dell’approccio utilizzato: dopo due anni di lavoro, il sistema raggiunge quasi il 95% di successi “al primo colpo”. Il valore aggiunto del sistema, inoltre, viene confermato dal supporto fornito ai nuovi operatori che non conoscono i dettagli specifici di quel processo di produzione.
Alla luce dei risultati ottenuti e considerando i dati raccolti nei due anni di lavoro, abbiamo progettato l’evoluzione del sistema presentato. Avendo a disposizione un consistente volume di dati, che sono stati raccolti in questi due anni, costruiremo la base di conoscenza con un approccio di tipo deep learning. Si tratta di un modello a rete neurale che presenta più strati nel layer hidden.
Il modello di rete scelto appartiene alla classe delle recurrent neural network (RNN), volendo rappresentare un comportamento dinamico dal punto di vista temporale. In effetti si manifestano relazioni tra i dati raccolti in istanti di tempo consecutivi: relazioni utili per comprendere l’evoluzione del sistema da uno stato di fault ad uno stato fault-less, a conferma dell’effettiva risoluzione del problema.
L’applicazione del deep learning è possibile grazie alla disponibilità di dati reali raccolti durante questi due anni di lavoro: nella prima versione si è scelto un approccio model based, che si contrappone ad approcci data driven [3], grazie all’implementazione di una base di conoscenza di tipo rete bayesiana dinamica, non avendo ancora la disponibilità dei dati.
In questo paper verrà presentato un caso reale, di cui verrà mostrato il layout dell’impianto e le macchine che lo compongono. Inoltre, saranno presentate le scelte innovative e i risultati ottenuti sperimentalmente, durante i due anni di lavoro.
Metodo
Il funzionamento del sistema è descritto nella Figura 1.
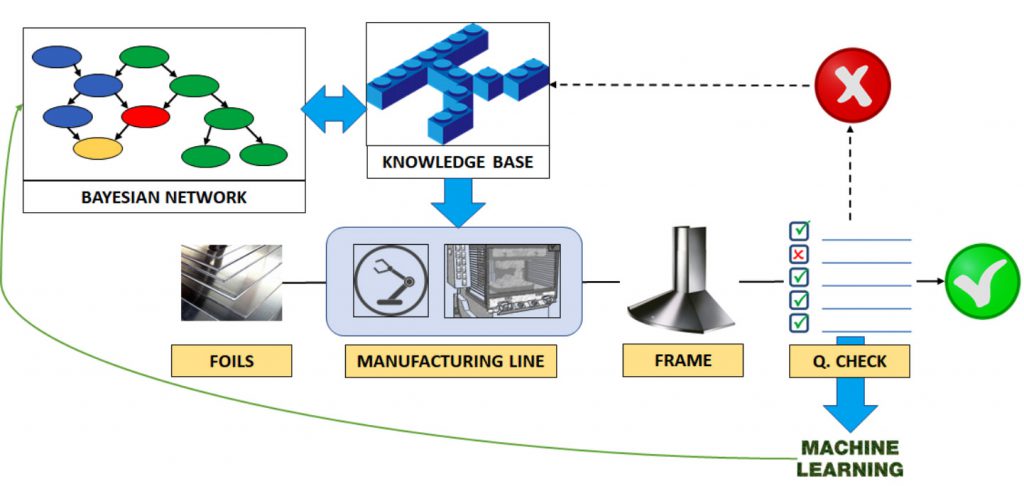
Come strumento di diagnosi è stata scelta la rete bayesiana perché è un modello che ben rappresenta una rete causale [4].
Le relazioni causa-effetto sono rappresentate dai nodi causa collegati ad i nodi effetto, tramite degli archi orientati. Su ogni arco è presente un pesoche rappresenta una probabilità condizionale: dato il verificarsi di un effetto, è la probabilità che quell’evento sia dovuto alla causaad esso collegata. In realtà, dalla teoria delle reti bayesiane, per ogni nodo andrebbe specificata una tabella delle probabilità condizionate (CPT). Le righe della CPT contengono le probabilità che il nodo abbia un valore veronelle differenti combinazioni (vero e falso) dei valori dei nodi padre. Quindi la CPT conterrà 2nrighe, dove nè il numero di nodi padre. Sotto certe condizioni [5]è possibile ridurre il numero di righe ad una per ogni arco.
La costruzione della rete bayesiana viene fatta assieme all’esperto del processo. Dopo la costruzione della rete bayesiana, il sistema è stato messo in funzione; nel momento è stato rilevato un problema di qualità il sistema ha proposto una diagnosi e un piano di soluzione. Al primo funzionamento la lista dei piani di soluzione era vuota. L’inserimento dei piani è stato deputato all’operatore esperto del processo. I piani presenti nella Knowledge Base vengono proposti in modo da massimizzare l’utilità attesa(teoria dell’Utilità).
Dopo l’esecuzione del piano, il sistema chiede un feedback all’operatore e aggiorna l’associazione tra il piano e lo stato del sistema che lo ha generato. Questa metodologia segue il modello dell’apprendimento per rinforzo(Reinforcement Learning).

Modello
La costruzione del modello ha richiesto diverse fasi che sono descritte in questo paragrafo. La Figura 2mostra le diverse fasi interessate.
Nella prima fase sono stati implementati i controlli sulle grandezze, rilevate tramite sensori, che potrebbero generare dei problemi di qualità (Figura 3).

Il modello si concretizza in carte di controllo a singola variabile per grandezze a valori continui, oppure controlli diretti per associazione dei valori, per variabili di tipo attributo (discrete).

Nella seconda fase è stata costruita la topologia della rete bayesiana. Dati gli effetti (nodi effetti) da monitorare, sono stati associati le cause (nodi causa) che li generano e le relazioni temporali. Nella terza fase sono stati definiti i pesi sugli archi di collegamento, tramite intervista all’esperto del processo di produzione, seguendo la metodologia dell’OR rumoroso [5]. La Figura 4fa riferimento alla costruzione della rete bayesiana.
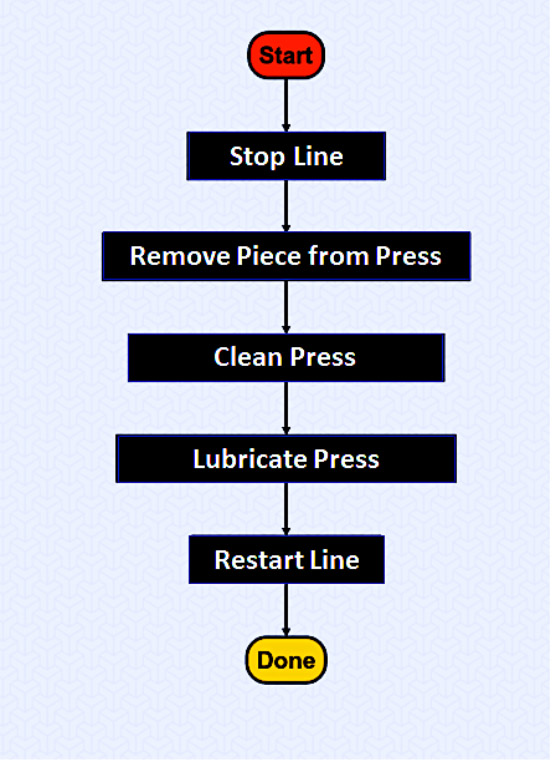
Una volta definita la rete bayesiana il sistema viene messo in funzione senza la presenza dei piani di azione. I piani vengono inseriti dall’operatore esperto, man mano che si verificano problemi di qualità. La funzione di utilità, che mette in relazione la conoscenza probabilistica dello stato del processo con il piano di azioni risolutore e massimizza l’utilità attesa, viene appresa dal sistema tramite reinforcement learning, considerando i feedback dell’operatore dopo lo svolgimento di un piano.
In Figura 5 un esempio di Action Plan.
Test Case
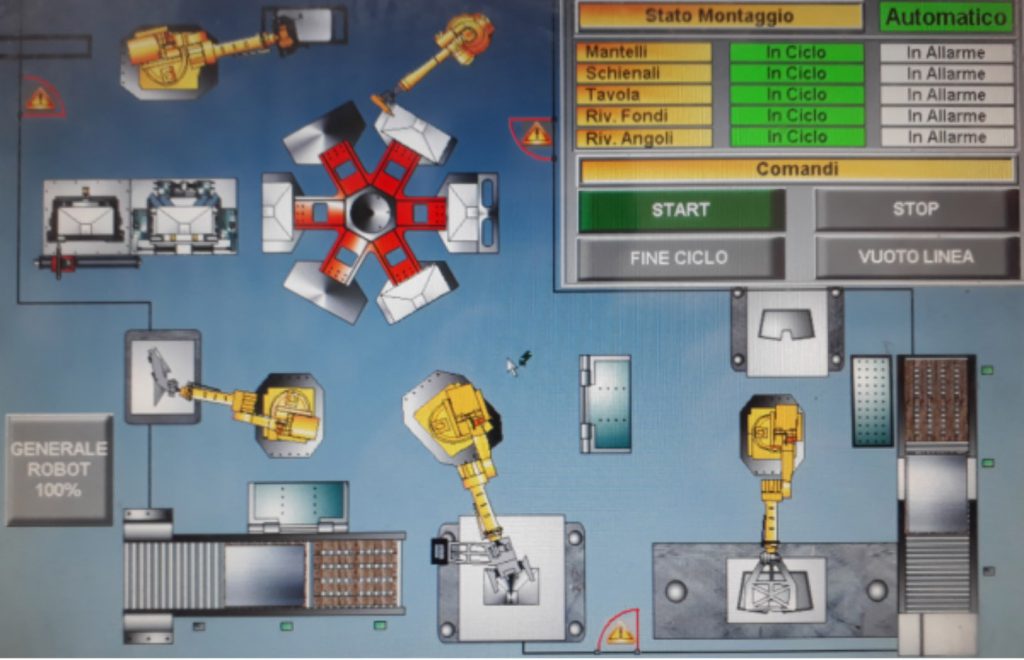
Il sistema è stato installato presso un plant produttivo di una multinazionale del settore metalmeccanico che produce elettrodomestici da cucina.
La Figura 6rappresenta la linea di produzione dove è in funzione il sistema dal 2018. La linea è costituita da: 5 robot, 2 presse di taglio, 2 presse di piega, 1 stazione rotativa e 3 postazioni di rivettatura.
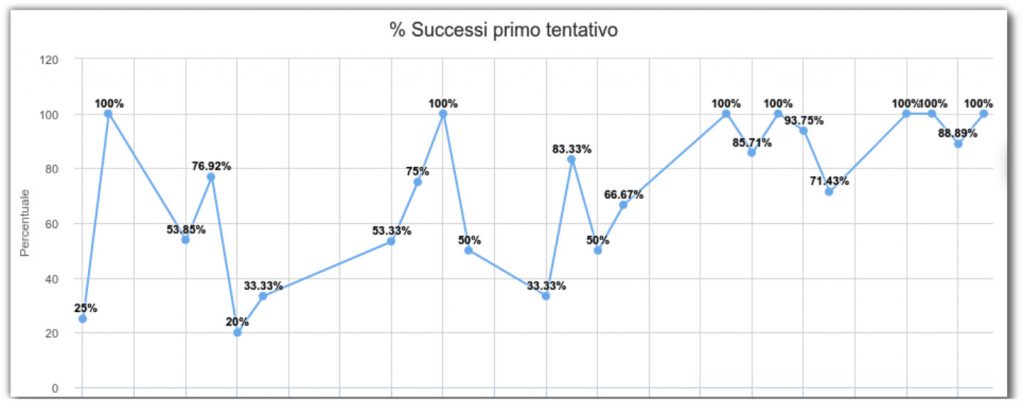
I risultati ottenuti sono mostrati nella Figura 7.
Come si vede nel grafico, dopo la prima fase di apprendimento, il sistema raggiunge il 95% di successi “al primo tentativo”; ovvero il primo piano di azioni proposto dal sistema è risultato risolutivo. Nei giorni con percentuale bassa di successo si sono verificati problemi di qualità “nuovi” per il sistema. Nei giorni con 100% di successo, al sistema sono stati presentati problemi simili a quelli già rilevati.
Sviluppi futuri
Nei due anni di lavoro il sistema ha raccolto una mole consistente di dati. Considerando la bontà dei dati raccolti, come evoluzione sperimentale del sistema, costruiremo la base della conoscenza con un approccio di tipo deep learning, il cui modello è rappresentabile tramite una rete neurale. In particolare, essa presenta, oltre agli strati di input e output, un certo numero di strati intermedi che contengono una quantità elevata di nodi, che hanno il compito di estrazione di caratteristiche e classificazione.
Le uscite della rete forniranno la distribuzione di probabilità sui possibili stati del sistema, così come attualmente svolto dalla rete bayesiana. Il vantaggio atteso, rispetto all’approccio bayesiano, riguarda la possibilità di poter discriminare le non linearità presenti nella distribuzione dei dati e di poter potenzialmente riusare la conoscenza acquisita tramite transfer learning, per altri impianti assimilabili.
Il modello di rete scelto appartiene alla classe delle recurrent neural network, volendo rappresentare un comportamento dinamico dal punto di vista temporale. Infatti, il fenomeno che si vuole rappresentare presenta delle correlazioni tra eventi accaduti all’istante ted eventi accaduti all’istante t-k. Un’anomalia nel processo di produzione verificatasi all’istante presenterà evidenze negli istanti temporali precedenti.
La costruzione della rete viene effettuata in due passi: costruzione della topologia, tuning dei pesi sui collegamenti durante la fase di training. La scelta della topologia (numero di livelli nascosti e relativi nodi) si effettua in modo sperimentale, selezionando quella che restituisce i risultati migliori. Il tuning dei pesi viene effettuato durante la fase di training, utilizzando il training set e un algoritmo di retropropagazione dell’errore. Essendo una rete neurale profonda, per l’aggiornamento dei pesi utilizzeremo un algoritmo che si basa sulla discesa stocastica del gradiente (SGD).
Bibliografia
- Ferracuti F., Giantomassi A., Longhi S., Bergantino N., Multi-scale PCA based fault diagnosis on a paper mill plant, 2011
- Cicconi P., Postacchini L., Bergantino N., Capuzzi G., Russo A.C., Raffaeli R., Germani M., A decision theory approach to support action plans in cooker hoods manufacturing, 2018
- Bergantino N., Caponetti F., Longhi S., FaultBuster: data driven fault detection and diagnosis for industrial systems, 2009
- Marcot B.G., Penman T.D., Advances in Bayesian network modelling: Integration of modelling technologies Environmental Modelling & Software, 2018
- Oniśko A., Druzdzel M.J., Wasyluk H., Learning Bayesian network parameters from small data sets: application of Noisy-OR gates, 2001
Biografia autori
Nicola BERGANTINO, n.bergantino@mynext.it
- 1994-1997: Software developer presso Esercito Italiano
- 1997-2002: Software developer presso software house BMP
- 2002-2010: CEO presso software house Integra
- 2011-2020: CTO e R&D Manager presso software house NeXT
- Pubblicazioni scientifiche
- 2019: A Design Approach for Overhead Lines Considering Configurations and Simulations
- publication dateNov 7, 2019 publication descriptionComputer-Aided Design and Applications
- 2018: A decision theory approach to support action plans in cooker hoods manufacturing
- publication dateJun 20, 2018 publication descriptionInternational Joint Conference on Mechanism, Design Engineering And Advanced Manucfacturing
- 2011: Multi-Scale PCA based fault diagnosis on a paper mill plant
- publication dateSep 9, 2011 publication descriptionETFA’2011 – IEEE International Conference on Emerging Technology & Factory Automation to be held in Toulouse, France
- 2009: FaultBuster: data driven fault detection and diagnosis for industrial systems
- publication description7th Workshop on Advanced Control and Diagnosis (ACD09)
- 2009: Fault tolerant software: a multi-agent system solution
- publication dateJul 3, 2009 publication descriptionIn 7th IFAC Symposium on Fault Detection, Supervision and Safety of Technical Processes
Gianluca CAPUZZI, g.capuzzi@mynext.it
- 2004 Laurea in Ingegneria Elettronica– Università Politecnica delle Marche
- 2008 Dottorato di ricerca in Sistema Artificiali Intelligenti– Università Politecnica delle Marche
- 2007- 2008 Assegno di ricercaSSD MAT09 – Università Politecnica delle Marche
- 2006 presentazione articolo in conferenza internazionale, IEEE CTS’06 Las Vegas, IRSS: Incident Response Support System Gianluca Capuzzi, Luca Spalazzi, Francesco Pagliarecci in Proceedings of the International Symposium on Collaborative Technologies and Systems
- 2006 presentazione articolo in conferenza internazionale, IEEE CTS’06 Las Vegas, Formal Definition of an Agent-Object Programming Language Francesco Pagliarecci, Luca Spalazzi, Gianluca Capuzzi in Proceedings of the International Symposium on Collaborative Technologies and Systems
- Posizione attuale, Project Engineer presso NeXT Srl di Jesi
Domenico CARBONE, d.carbone@mynext.it
- 1998: Laurea in Lettere Moderne presso l’Università degli Studi di Perugia
- 1999: frequenta e porta a conclusione un corso formativo per “Webmaster” presso il Comune di Fabriano
- 2000: lavora presso il “Laboratorio delle Idee srl” in qualità di formatore a distanza e presenza, social media manager e multi media manager
- 2007: riceve il premio della critica da parte del critico cinematografico Morando Morandini al “Festival internazionale del fumetto” di Dervio, per fumetto illustrato dalla disegnatrice Federica Giulietti, del quale ha scritto la storia
- 2015: consegue il master in “Web marketing” presso Ninja Marketing
- 2016: inizia a lavorare presso “NeXT srl” in qualità di digital strategist e blogger. È autore di numerosi articoli presentati in riviste specializzate in Industria 4.0 e manifattura.





{kind=link}